
New York Times v. OpenAI/MS
No to się zaczęło…
Chwilę temu kilka korporacji informacyjnych rozpoczęło negocjacje z OpenAI oraz Microsoft (MS) dotyczące wzajemnej współpracy. Ta współpraca to z jednej strony wykorzystywanie modeli LLM przy wsparciu tworzenia treści dla pism/portali, z drugiej dostęp do materiałów, które są potężną bazą do uczenia tychże modeli. Klika pism się dogadało (np. Axel Springer, Associated Press), a kilka nie (np. New York Times /NYT/).
Na decyzję NYT na pewno wpływ miały pozwy autorów, którzy oskarżyli koncern o wykorzystywanie ich materiałów z naruszeniem praw autorskich. W sierpniu 2023r koncern zmienił swoją politykę i oświadczył, że jego treści nie mogą być wykorzystywane „do celów programistycznych dowolnego oprogramowania, w tym między innymi szkolenia w zakresie systemów uczenia maszynowego lub sztucznej inteligencji (AI)„.
Teraz mamy kolejny krok – formalne oskarżenie OpenAI i Microsoft-u o wykorzystywanie materiałów NYT z naruszeniem praw autorskich. NYT wskazuje na potrzebę formalnego procesu z udziałem ławy przysięgłych, aby właściwie ocenić działania OpenAI/MS, skalę naruszeń oraz właściwą wysokość kary. Na dowód tych praktyk przedstawia swoje materiały, mające pokazać skalę tego zjawiska (część materiałów przedstawił sp+ w swoim artykule). Wzywa też pozwanych do „trwałego zakazanie Pozwanym niezgodnego z prawem, nieuczciwego i naruszającego postępowania”. Oznacza to de facto zniszczenie podstawowego narzędzia OpenAI (ChatGPT) oraz innych tego typu modeli wykorzystywanych przez te firmy. Swoje stanowisko NYT przedstawia w obszernym liście do czytelników.
Wygląda więc na to, że ziszczają się kolejne prognozy dotyczące sposobu wykorzystywania AI (wiem, nie jest całkiem właściwe określenie). Materiały powstają przy współpracy modeli LLM (lub są tworzone tylko przez modele LLM – przypadek Sports Illustrated się tu kłania). Do uczenia modeli używanych jest miliony stron różnych treści, o którym to procederze autorzy tych treści nie są informowani. Wykorzystywanie AI na szeroka skalę zapowiada Axel Springer, który już oświadczył, że wykorzystywanie tych technologii będzie wykorzystywane do poprawy kondycji firmy (należy to czytać z uwzględnieniem kontekstu, np. opisanego tu).
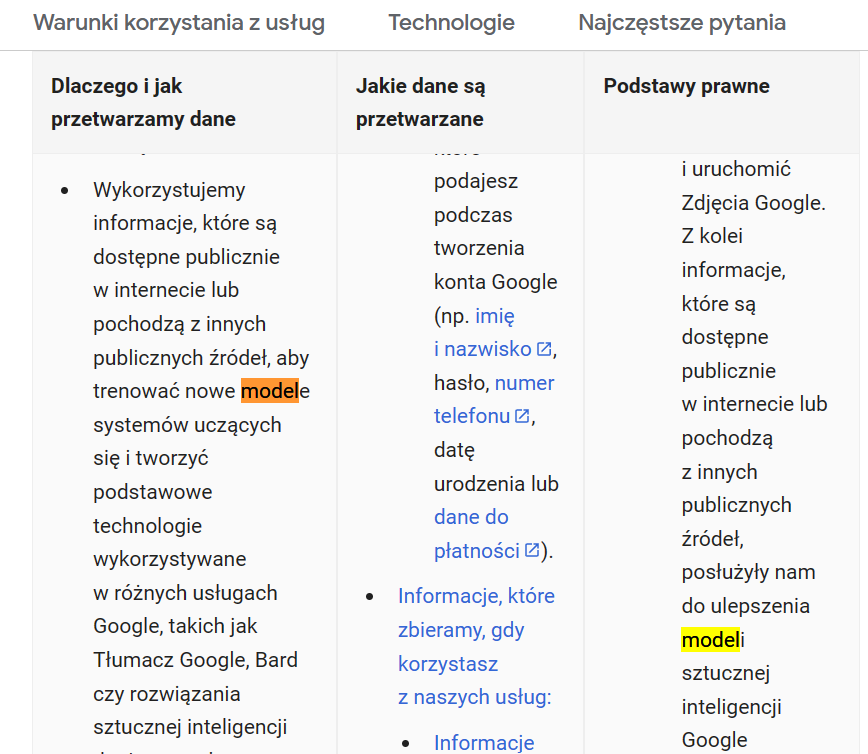
A Wy, drodzy użytkownicy usług Google, czy wiecie że też 'karmicie’ AI swoimi danymi? I do tego jeszcze czasem za to płacąc? Sprawdzicie swoje 'Terms of Services’:
Grzegorz Pająk

Audyt stron internetowych

Nowy kodeks postępowania w ochronie danych osobowych
